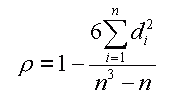| Rome University, La Sapienza Chemistry Department Rome, Italy, Europe |
Dr. Giovanni Visco Cenni di statistica di base. Calcoli di regressioni e correlazioni dicembre 2006 |
Corso di Laurea in: Scienze Applicate ai Beni Culturali ed alla Diagnostica per la loro Conservazione Corso di laurea in: Chimica Ambientale |
| previous slide, 30 | all lessons, these slides index | next slide, 32 |
Questa volta la citazione storica e' davvero necessaria, bisogna inquadrare il periodo storico di nascita del test. Charles Edward Spearman (1863-1945) ha sviluppato il test, nel 1904, per testare statisticamente se due set di dati, diciamo due distribuzioni, sono fra loro correlate. Trovate citato il test nei libri anche come "Spearman Rank-Order Correlation Coefficient"
Il test deve essere utilizzato per valutare se esiste una relazione fra due serie di misure, e misurarne l'affiatamento.
Su questo test c'e' qualche piccola confusione. L'ambiguita' e' nel metodo di calcolo e nell'applicazione alle misure come anche nell'interpretazione dei risultati, qui daremo l'interpretazione originale e comunque anche alcuni web-riferimenti. Qualche autore lo cita anche al contrario come test di indipendenza fra due variabili. I riferimenti: A pragmatic Approach, Rank-Order Correlation, Spearman's rho.
Questo test puo' essere utilizzato con variabili almeno Ordinali, ma anche per distribuzioni abbastanza diverse dalla Gaussiana e per set di misura con numerosita' diversa.
Non fate confusione! La correlazione di Spearman e' definita come una relazione monotonica dove Y cresce o descresce continuamente in funzione di X. Questa correlazione puo' essere analizzata sostituendo ai singoli valori di X e di Y la loro posizione nell'insieme delle osservazioni. Sembra tanto il test ma e' un altra cosa
Due variabili misurano, con scale almeno ordinali, una serie di oggetti, anche virtuali, e vogliamo essere certi che la varianza di una variabile NON sia correlata con la varianza dell'altra variabile.
Sarebbe meglio se gli oggetti fossero estratti casualmente dalla popolazione, che nessuna delle variabili sia affetta da bias, che gli eventuali sampling desings siano ben condotti.
| Misura n. | I | II | III | IV | V | VI | VII | VIII | IX | X | XI | XII | XIII |
| altezza, m | 1.58 | 1.63 | 1.60 | 1.69 | 1.74 | 1.92 | 1.62 | 1.91 | 1.58 | 1.79 | 1.88 | 1.65 | 1.78 |
| scarpa num. | 37 | 37 | 36.5 | 38 | 44 | 45 | 39 | 46 | 38 | 39 | 44 | 38 | 43 |
Il data set a disposizione e' composto da 112 interviste ma ne sono state estratte solo 13 mediante un campionamento simple random sampling without replacement. Non apriamo qui la discussione sul dominio di studio, sull'area di interesse, etc..
Definizioni:
*un esempio che potete leggere qui e' il costo di una bibita in funzione della distanza da un "evento" (una partita, un concerto, ecc.), l'oggetto nascosto e' l'ingordigia di chi sfrutta una rendita di posizione.
|
Calcoli: Per prima cosa costruiamo una tabella da 5 colonne, la prima e la seconda sono le due variabili, le altre tre piene di zeri. Mettiamo in ordine crescente la tabella per la prima colonna, nella terza ora calcoliamo e scriviamo i rank collegati alla prima colonna. Riordiniamo ora la tabella per la seconda colonna, ora nella 4 colonna calcoliamo e scriviamo i rank collegati alla colonna 2. Anche se non necessario ora vari autori riordinano per la terza colonna (il rank di A). Finalmente nella colonna 5 calcoliamo d2=(rankA-rankB)*(rankA-rankB) per ogni oggetto. Nel calcolare i ranks bisogna fare attenzione sia a mantenere il collegamento fra i due set di misure e l'oggetto, sia alla somma dei ranks che deve dare il valore calcolato con la solita formula. Agli estremi si possono ottenere due casi.
Come gia' detto il test prevede che per la correlazione diretta si ottenga il valore ρ=+1 , e per la correlazione inversa, esatta, ρ=-1. Ora bisogna trovare una formula matematica che, dato il numero di oggetti (n), e data la somma dei quadrati (d2) appena calcolata, ci porti a questo risultato. Qualche prova con 3, 4, 5 oggetti ci porterebbe a generalizzare la formula:
Data la formula nel nostro caso abbiamo ρ (rho) = +0.8475 che dobbiamo interpretare. Il valore sembra vicino al massimo, +1 e percio' dovrebbe indicare una accentuata correlazione fra le due misure. |
Data l'ipotesi H0 che non vi sia covarianza fra le due misure ora dobbiamo calcolare quanto e' significativo il valore trovato. Come al solito i valori di significativa' sono al 95%, al 98%, al 99% a seconda di quanto accettiamo di errore sulla H0.
La maggior parte dei testi oggi consigliano la Boostrap Analysis o Permutation Analysis ma i vecchi metodi gia' visti di confronto dei dati con una tabella si possono ancora usare. Trovando la tabella giusta, questa? (Sussex University).
Scelto il 95%, cioe' 0.05 in tabella, dato n=13 nel nostro caso (in tabella scegliamo lui od il piu' piccolo, 12) troviamo 0.591 che ci da quale potrebbe essere ρ dovuto al solo caso statistico, dato che il nostro valore e' ben superiore l'ipotesi H0 e' rifiutata. Lo sarebbe anche per il 98% ed il 99% nel caso in esame.
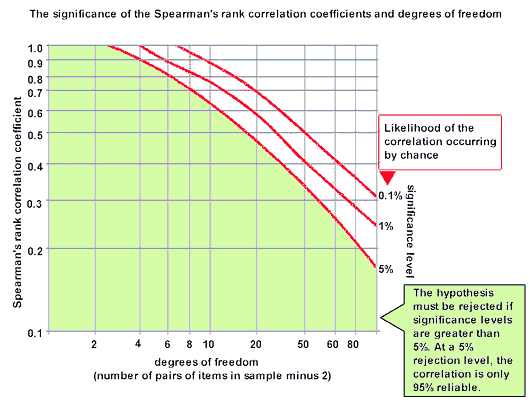 |
| Un bel grafico per il calcolo della significativita' di ρ. Fate attenzione che la scala X e' logaritmica e misura i gradi di liberta'. Preso qui. |
Sono disponibili almeno due calcolatori-on-line per il Spearman rank test. Questo calcolatore lo trovate presso il solito Vassar College, anche l'altro calcolatore e' su di un sito famoso, Wessa.net del Prof. Patrick Wessa.
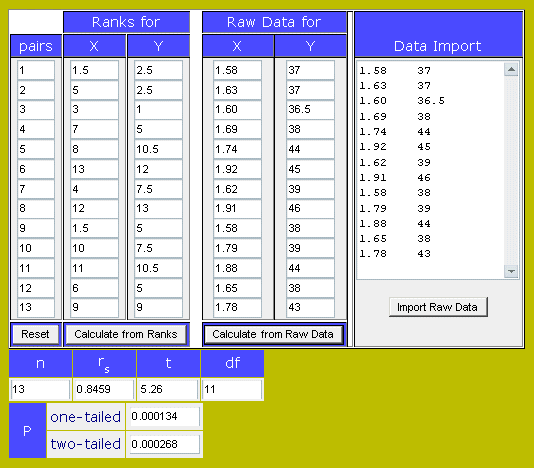 |
| La solita confusione, qui ρ viene chiamato rs. Anche il valore e' un poco diverso da quello calcolato con la formula perche' e' corretto tenendo conto dei gradi di liberta' |
Se la vostra subnet e' compresa in quelle che hanno accesso alla risorsa potete anche visualizzare il bellissimo articolo: Jerrold H. Zar, Significance Testing of the Spearman Rank Correlation Coefficient, Journal of the American Statistical Association, Vol. 67, No. 339 (Sep., 1972), pp. 578-580, con le formule e le correzioni. Io ne ho una copia.
Non e' necessario che i due set di dati (cioe' le due variabili) siano due misure dello stesso oggetto. Proprio per questo il test e' una vera stima della correlazione, come il Pearson ed il Kendal test.
Per esempio nel caso del campionamento delle nostre provette potremmo correlare i 13 valori prodotti dal simple random sampling with replacements con i valori prodotti dal systematic sampling with a random start.
L'interpretazione dei risultati e' ben piu' complessa, praticamente stiamo confrontando le due distribuzioni per come siamo riuscite a leggerle attraverso i due campionamenti. Per il fondo della provetta sappiamo trattasi di una bimodale e se i campionamenti hanno fatto un buon lavoro l'ipotesi H0 non dovrebbe essere soddisfatta.
Pero' molti autori non usano il test di Spearman per questo confronto ma bensi' il Kendall τ test, vedremo fra qualche slide.
| previous slide, 30 | all lessons, these slides index | next slide, 32 |