| Rome University, La Sapienza Chemistry Department Rome, Italy, Europe |
Dr. Giovanni Visco Cenni di statistica di base. Calcoli di regressioni e correlazioni. dicembre 2006 |
Corso di Laurea in Scienze Applicate ai Beni Culturali ed alla Diagnostica per la loro Conservazione |
| previous slide, 52 | next slide, 54 |
Fino ad ora praticamente tutti i test erano legati la valore centrale di una distribuzione, nelle sua varie forme, e su questo basavano le ipotesi, magari tenendo conto anche dello spread.
R.A. Fisher invece in gran parte dei suoi studi di statistica si interessa della varianza, cioe' della forma e della dispersione di una distribuzione. E' un grande passo avanti che ci permettera' la nascita di altri test non solo fra due variabili ma anche multivariati.
Qualche ipotesi preliminareDato che anche se basato sulle varianze anzi per essere precisi sugli scarti quadratici medi dei campioni si tratta pur sempre di un test parametrico con alcune premesse per la sua validita'.
The F-test is used to test if the standard deviations of two populations are equal. Definiamo due distribuzioni, anche di numerosita' poco diversa, che provengono dal campionamento di una popolazione. Come nell'esempio seguente che abbiamo gia' usato per un non-parametrico.
| Random sampling with replac. | 14.71 | 14.83 | 14.71 | 14.79 | 14.78 | 14.80 | 14.64 | 14.68 | 14.80 | 14.78 | 14.71 | 14.77 | 14.70 |
| Systematic sample | 14.70 | 14.80 | 14.80 | 14.73 | 14.82 | 14.77 | 14.73 | 14.70 | 14.75 | 14.78 | 14.76 | 14.81 | 14.79 |
Questo F-test cosi' detto in onore a R.A. Fisher e' usato per confrontare due varianze σa e σb mediante due loro stime Sa et Sb. Il test e' normalmente definito con la sigla F(a,b). Il test e' utile perche' una volta dimostrata la H0 ci permette di stimare σa conoscendo Sa.
Definizioni:
Calcoli:
Vista la delicattezza intrinseca dei test parametrici e meglio, come al solito, graficare le due distribuzioni. Usiamo un ampiezza di classe pari a due volte la risoluzione, 0.02 mm. Notiamo che una volta riportate in grafico le due distribuzioni si presentano davvero difficili, altro che mediana e average, queste sono indefinite e' non potrebbero essere usate in un test parametrico.
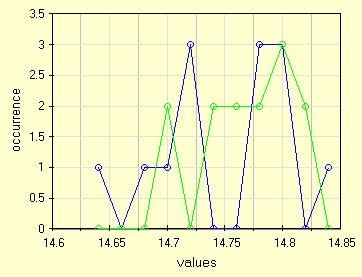 |
| le due distribuzioni per il test di Fisher sulle varianze |
Anche se qualche volta c'e' qualche confusione sulla notazione, la formula e' chiara. Ricordiamo che le due varianze vanno poste con S2a > S2b, cosi' facendo si avra' sempre F(a,b) > 1.
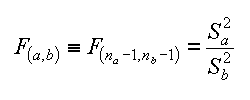 |
| F-test, variance ratio |
Che nel caso delle due distribuzioni da 13 misure:
Le tavole dei valori critici di Fisher sono di solito costruite per valori di probabilita' del 90%, 95% et 99%. Inoltre queste tabelle sono tutte one-side, questo per la particolare forma della distribuzione F. Percio' usiamo una tabella one-side per confermare una H0 per σa=σb che sembrerebbe aver bisogno di tabelle double-side, risultato ... usiamo per il test la tabella α/2. Ma questo, a parte una spiegazione a lezione, esula un po dal nostro insegnamento.
Percio' in questo caso accettiamo un errore di tipo I pari al 10% ed al 2%, cioe' una probabilita' per H0 pari al 90% ed al 98% (che indica anche una α=0.1 et α=0.02). Copiamo le opportune tabelle α/2 da un un buon libro.
| One Sided Fisher critical values for α=0.05 | ||||||
|---|---|---|---|---|---|---|
| S2b | 10 | 11 | 12 | 13 | 14 | <--- S2a |
| 10 | 2.978 | 2.943 | 2.913 | 2.887 | 2.865 | |
| 11 | 2.854 | 2.818 | 2.788 | 2.761 | 2.739 | |
| 12 | 2.753 | 2.717 | 2.687 | 2.660 | 2.637 | |
| 13 | 2.671 | 2.635 | 2.604 | 2.577 | 2.554 | |
| 14 | 2.602 | 2.565 | 2.534 | 2.507 | 2.484 | |
Avendo scelto una probabilita' del 90% (ricordiamoci α/2) il valore tabulato 2.687 e' maggiore di quello ottenuto 2.013 percio' l'ipotesi nulla e' accettata.
| One Sided Fisher critical values for α=0.01 | ||||||
|---|---|---|---|---|---|---|
| S2b | 10 | 11 | 12 | 13 | 14 | <--- S2a |
| 10 | 4.849 | 4.772 | 4.706 | 4.650 | 4.601 | |
| 11 | 4.539 | 4.025 | 4.397 | 4.342 | 4.293 | |
| 12 | 4.296 | 4.220 | 4.155 | 4.100 | 4.052 | |
| 13 | 4.100 | 4.025 | 3.960 | 3.905 | 3.857 | |
| 14 | 3.939 | 3.864 | 3.800 | 3.745 | 3.698 | |
Se abbiamo scelto una probabilita' del 98% (ricordiamoci α/2) il valore tabulato 4.155 e' anchesso maggiore di quello ottenuto 2.013 percio' l'ipotesi nulla e' accettata.
In questo esempio si vede ancora meglio il funzionamento della matrice 2x2 legata alle ipotesti H0 ed H1. Se accettiamo di commettere un errore di tipo 1 (cioe' che H0 e' vera ma noi la rifiutiamo) con un α=0.02 il valore di F(a,b) deve essere molto grande; la nostra forte preoccupazione di non commettere errori del I tipo ci fa accettare valori di F(a,b) molto grandi fino a 4.155. Forse per questo, ma non solo, il test piu' usato e' quello con α=0.05, il 95%.
on-line resourcePrima una precisazione: sono state lasciate tutte le cifre decimali prodotte dai calcoli per permettere il confronto con altri software, chiaramente se questi numeri comparissero in una pubblicazione e/o relazione sarebbero sbagliati.
The F-test can be also used to estimate how many measures are necessary to obtain a stated α. Cioe' possiamo chiederci, "definita una probabilita' α, quanti dati servono affinche l'ipotesi nulla possa essere accettata o respinta con una probabilita' β di comettere errori di tipo II?".
Le formule non sono dovute a Fisher ma utilizzano la sua distribuzione e quella di Gauss per stimare un numero minimo di misure. Una delle formule:
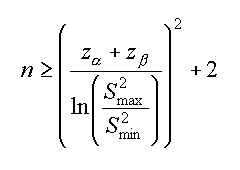 |
| Raghavarao estimation of nmin |
In cui, con i soliti parametri:
Lo stimare quanti dati saranno necessari per il nostro test e' detto dagli statistici stimare la "Potenza a Priori". Parametro necessario ma che implica delle assunzioni sugli errori del I e del II tipo, anzi sul loro legame come si vede dal numeratore delle formula, che spesso sono difficili o aleatorie.
Sulla formula e sul concetto qui espresso ci sarebbe da dire tanto, e' una tautologia, per "stimare" devo gia' conoscere Sa et Sb cioe' ha gia' svolto le misure su di un umero n di oggetti. Allora la formula ci dice se il numero n usato e' sufficiente se avessimo scelto richeisto un valore di α e β. Questo giusto per far capire le implicazioni che ci sono dietro una formula ed una scelta.
Sui testi di statistica si trovano varie formule che esula dal nostro contesto. Per pochi campioni, cioe' nella numerosita' prevista da Gosset si puo' usare una criterio per diminuire la soggettivita' nella scelta di α e β, legandoli fra loro con la formula.
1-β = 1-4α
Magari dopo aver riletto la slide su H0 ed H1 e su "errore di tipo I" ed "errore di tipo II" e "costo dell'errore" possiamo esplicitare i casi piu' frequenti:
α=0.01 e β=0.05 oppure α=0.02 e β=0.10 ed anche α=0.05 e β=0.20
P.S.I valori di Z li trovate in tante tabelle e ne abbiamo parlato anche in una slide (z che sottende il 95% dei dati
| previous slide | next slide |