| Rome University, La Sapienza Chemistry Department Rome, Italy, Europe |
Dr. Giovanni Visco Cenni di statistica di base. Calcoli di regressioni e correlazioni. dicembre 2006 |
Corso di Laurea in Scienze Applicate ai Beni Culturali ed alla Diagnostica per la loro Conservazione |
| previous slide, 51 | next slide, 53 |
... Little experience is sufficient to show that the traditional machinery of statistical processes is wholly unsuited to the needs of practical research. Not only does it take a cannon to shoot a sparrow, but it misses the sparrow! The elaborate mechanism built on the theory of infinitely large samples is not accurate enough for simple laboratory data. Only by systematically tackling small sample problems on their merits does it seem possible to apply accurate tests to practical data. Such at least has been the aim of this book. (Sir Ronald Aylmer Fisher, 1925/34, preface of "Statistical Methods for Research Workers", 978-0198522294)
Ma scopo del corso NON e' spiegare il testo di W.S. Gosset (non essendo noi R.A.Fisher puo' essere tanto difficile spiegare quanto facile sbagliare!) ma descrivere qualche applicazione del test di Student che tanto si trova citato e qualche volta a sproposito. Ma per far questo e' nata una delle silde piu' lunghe!
Abbiamo invece capito che i test non-parametrici gia' visti, il campionamento statistico, qualche misura in meno ma con piu' qualita', ci permettono/impongono nei settori dei Beni Culturali e nell'Ambiente "samples", cioe' piccoli numeri da trattare con attenzione per essere Pertinenti e Rappresentativi.
Dato che di t-test ce ne sono almeno 4 (anzi forse 5) e per capire come usarli si possono leggere 9 libri senza risolvere nulla (ma forse basta leggere 978-0942154917 et 978-0942154993). Meglio iniziare con una descrizione delle condizioni necessarie affinche' questo ed altri test parametrici abbiano validita':
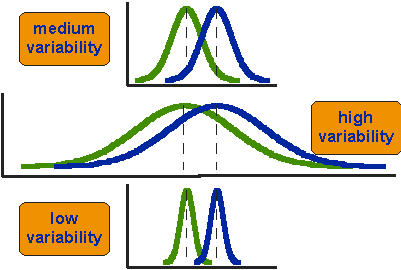
Tutti i t-test hanno la struttura di un rapporto [ratio structure], cioe' sono una misura del rapporto segnale/rumore [signal/noise ratio]. Il numeratore e' la differenza fra due medie, fra una misura e la media o similare, cioe' la differenza fra due segnali reali e misurabili; il denominatore misura la variabilita', cioe' la dispersione, cioe' il rumore che la casualita' inserisce nella/nelle misure. Una immagine di esempio, stessa differenza fra i segnali ma ben diverso e' il rumore.
 |
| from: http://www.socialresearchmethods.net/kb/stat_t.php |
Visti nell'ottica S/N ratio tutti i test si semplificano, bisogna solo trovare cosa mettere sopra e sotto la linea di frazione e decidere quanto "rumore" accettare. Nel secondo caso delle figura qui sopra non saremo mai sicuri della reale differenza fra le due distribuzioni; nel terzo caso invece il t-test dovrebbe mostrarci la loro diversita'.
Test whether the mean of one variable differs from a constant. Dato un campionamento con n oggetti di una popolazione, con le solite limitazioni viste prima, possiamo calcolare la varianza del campione, il suo S, la sua media X soprasegnato (X bar).
Della popolazione potremmo aver misurato con qualche altro metodo la media μ, ed invece cerchiamo la media attesa che dovremmo prevedere dal campionamento detta μ0. Come al solito possiamo usare uno dei campionamenti delle provette.
| Count n. | 4 | 14 | 24 | 34 | 44 | 54 | 64 | 74 | 84/td> | 94 | 104 | 114 | 124 |
| values, mm | 15.03 | 15.07 | 15.13 | 15.03 | 15.05 | 15.08 | 15.05 | 15.13 | 15.10 | 15.12 | 15.09 | 15.06 | 15.06 |
A quanto sembra il random start era' 4.
Questo t-test di Gosset e' quello per confrontare una media osservata con una media attesa. Il test e' normalmente definito con la sigla t(n-1). Il vero t-test confronterebbe la media campionaria con la media della popolazione ma spesso quest'ultima e' incognita.
Definizioni:
Calcoli:
Riaffermando che i test parametrici sono "delicati" e basta una svista per inficare un risultato, come al solito prima grafichiamo la distribuzione, visto che abbiamo un numero sufficiente di valori per formare delle classi. Usiamo un ampiezza di classe pari a due volte la risoluzione, 0.02 mm.
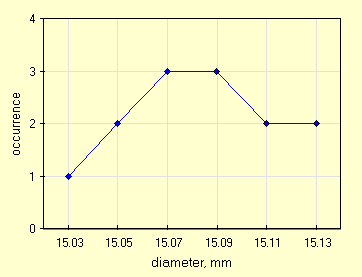 |
| distribuzione per classi, 13 dati |
Per mezzo di 4 campionamenti otteniamo una μ0=15.09 (dovuta a disegni differenti, ma con qualche ripetizione).
Di formule se ne trovano tante, complesse, semplici, palesemente sbagliate, questa speriamo sia quella giusta.
 |
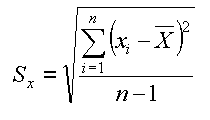 |
| la media campionaria verso l'attesa | formula di Sx |
In cui, nel caso dei 13 diametri delle provette sotto il tappo:
Come al solito facciamo due test con probabilita' al 80% ed al 95% (cioe' α=0.2 et α=0.05). Copiamo una tabella da un buon libro.
| One Sided | 80% | 90% | 95% | 97.5% | 99% | 99.5% | 99.75% | 99.9% | 99.95% |
| Two Sided | 60% | 80% | 90% | 95% | 98% | 99% | 99.5% | 99.8% | 99.9% |
| 11 | 0.876 | 1.363 | 1.796 | 2.201 | 2.718 | 3.106 | 3.497 | 4.025 | 4.437 |
| 12 | 0.873 | 1.356 | 1.782 | 2.179 | 2.681 | 3.055 | 3.428 | 3.930 | 4.318 |
| 13 | 0.870 | 1.350 | 1.771 | 2.160 | 2.650 | 3.012 | 3.372 | 3.852 | 4.221 |
Se abbiamo scelto una probabilita' del 80% il valore tabulato 1.356 e' maggiore di quello ottenuto 1.326 (preso come modulo) percio' l'ipotesi nulla e' accettata.
Se abbiamo scelto una probabilita' del 95% il valore tabulato 2.179 e' maggiore di quello ottenuto 1.326 percio' l'ipotesi nulla e' accettata. Cioe' possiamo scrivere: -2.179 < t < 2.179 visto che usiamo un test a due code.
Ricordiamo che: a) della nostra esercitazione usiamo i diametri misurati sotto il tappo che sappiamo essere quasi una gaussiana, b) sulla definizione di media attesa ci sono cento definizioni!
Often are used to compare the means of two independently sampled groups. Utile per compare le medie di due distribuzioni ottenute dal campionamento di una sola popolazione. Questo sarebbe uno dei veri t-test, qualche volta e' anche utilizzato per comparare: due gruppi di pazienti con due diversi trattamenti; due misure di durata di una serie di lampadine, ma distorcendo il test.
Veramente di questi ce ne sarebbero tre, questi di seguito, ma se scriviamo la formula dell'ultimo, il c), questa dovrebbe andar bene anche per i primi due, magari semplificandola.
| Extr. n. | I | II | III | IV | V | VI | VII | VIII | IX | X | XI | XII | XIII |
| A values, mm | 15.10 | 15.09 | 15.10 | 15.09 | 15.06 | 15.12 | 15.03 | 15.10 | 15.08 | 15.10 | 15.05 | 15.04 | 15.11 |
| B values, mm | 15.08 | 15.02 | 15.05 | 15.10 | 15.07 | 15.07 | 15.05 | 15.10 | 15.11 | 15.09 | 15.11 | 15.10 | 15.08 |
Questa volta e' ancora piu' importante definire il t-test di Gosset, quello per confermare che due medie campionarie provengono dalla stessa popolazione. Il test e' normalmente definito con la sigla t(n1-n2). Oppure definito come t(n1+n2-2). Ma quella del punto c) e' anche definito come t i.
Definizioni:
Calcoli:
Date due distribuzioni una rappresentazione grafica gia' da sola puo' aiutare a comprendere la similarita', anche se non puo' misurarla. Usiamo anche questa volta una ampiezza di classe pari a 0.20 mm.
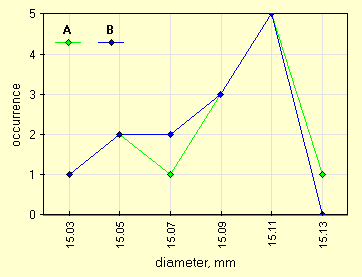 |
| le due distribuzioni campionarie, na=13, nb=13 |
Il solito problema di trovare le formule giuste, forse queste. Avevamo detto che iniziavamo con unequal sample sizes, unequal variance.
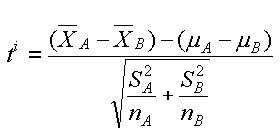 |
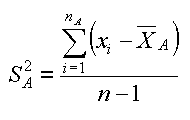 |
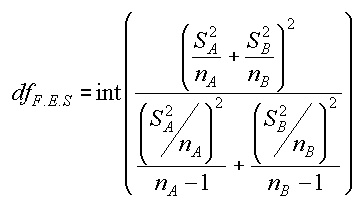 |
| t-test, 2 campionam. indip., diff. varianze | solita formula di S2, per SA et SB | degrees of freedom, by F. E. Satterthwaite, 1946 |
La formula per il calcolo dei gradi di liberta' non e' la solita n-1 ma una formula di approssimazione di F.E. Satterthwaite (An Approximate Distribution of Estimates of Variance Components, Biometrics Bulletin, 2(6), 1946, 110-114).
Nella formula del calcolo di ti l'espressione (μA-μB) e' uguale a zero vista l'ipotesi H0. Questo e' un ragionamento sottile, se confermeremo H0 abbiamo fatto bene ad annullarla, se non la confermeremo non potevamo cancellare questa differenza.
Da cui, nel caso delle 13+13 misure dei diametri delle provette:
Vista la piccola differenza fra le varianze avremmo potuto anche usare una formula riodotta per unequal sample sizes, equal variance.
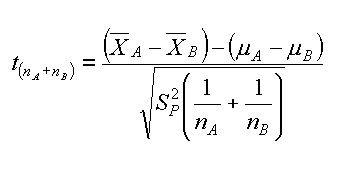 |
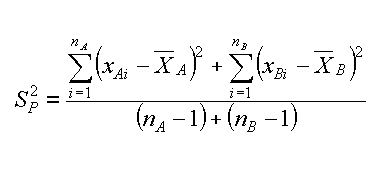 |
| t-test, 2 campionam. indip., uguali varianze | formula di S2, pooled |
Queste due formule danno un risultato molto simile per il test, ma i gradi di liberta' questa volta sarebbero df=(nA-1)+(nB-1)=24, uno in piu' di quelli calcolati con la formula precedente. Come al solito facciamo due test con probabilita' al 80% ed al 95% (cioe' α=0.2 et α=0.05). Copiamo una tabella da un buon libro.
| One Sided | 80% | 90% | 95% | 97.5% | 99% | 99.5% |
| Two Sided | 60% | 80% | 90% | 95% | 98% | 99% |
| 22 | 0.858 | 1.321 | 1.717 | 2.074 | 2.508 | 2.819 |
| 23 | 0.856 | 1.319 | 1.714 | 2.069 | 2.500 | 2.807 |
| 24 | 0.857| 1.318 |
1.711 |
2.064 |
2.492 |
2.797 |
|
| 25 | 0.856 | 1.316 | 1.708 | 2.060 | 2.485 | 2.787 |
Se abbiamo scelto una probabilita' del 80% il valore tabulato 1.319 e' maggiore di quello ottenuto 0.284 percio' l'ipotesi nulla e' accettata.
Con una probabilita' del 95% il valore tabulato 2.069 e' maggiore di quello ottenuto 0.284 percio' l'ipotesi nulla e' accettata. Cioe' possiamo scrivere: -2.069 < ti < 2.069 visto che usiamo un test a due code.
Anche usando la formula approssimata e 24 df si avrebbe lo stesso risultato stando cosi' lontani dai valori di soglia.
Used to compare means where the two groups are correlated, as in before-after, repeated measures, matched-pairs, or case-control studies. Usato quando le due distribuzioni sono correlate. In questo esempio prima del campionamento 11 provette sono state misurate dai 3 gruppi di lavoro proprio per vedere se c'e' qualche differenza significativa fra i gruppi. Cioe' studiamo cosa si ottiene usando lo stesso strumento/oggetti ma un diverso operatore inserito in un diverso contesto lavorativo.
Anche di questo t-test ce ne sarebbero due, questi: a) compariamo la ripetizione delle misure su n oggetti e NON ci aspettiamo una differenza b) ci aspettiamo che una qualche modifica sugli oggetti ABBIA prodotto una differenza pari a δ.
Sembrano la stessa cosa ma dietro questa sottile differenza ci sono miliardi di euro di eventuali profitti da parte di qualche casa produttrice di XYZ, migliore di YXZ.
| tube n.. | 44 | 54 | 96 | 120 | 119 | 124 | 9 | 83 | 98 | 10 | 30 |
| A values, mm | 15.13 | 15.13 | 15.12 | 15.11 | 15.10 | 15.11 | 15.07 | 15.08 | 15.10 | 15.10 | 15.09 |
| B values, mm | 15.07 | 15.12 | 15.11 | 15.13 | 15.16 | 15.08 | 15.10 | 15.09 | 15.11 | 15.13 | 15.15 |
| differences D=A-B | +0.06 | +0.01 | +0.01 | -0.02 | -0.06 | +0.03 | -0.03 | -0.01 | -0.01 | -0.03 | -0.06 |
Come al solito a questo punto la definizione del t-test di Gosset, questo e' per confrontare le differenze fra le misure appaiate ripetute sugli STESSI oggetti. Il test e' normalmente definito con la sigla td. Oppure definito come tδ.
Definizioni:
Calcoli:
Questa volta i grafici possibili sono due, quello classico con la distribuzione per classi (dopo una attenta scelta dell'ampiezza di classe), l'altro e' il Ladder Graph che puo' essere usato anche nel Wilcoxon Matched-Pairs Test che abbiamo gia' visto.
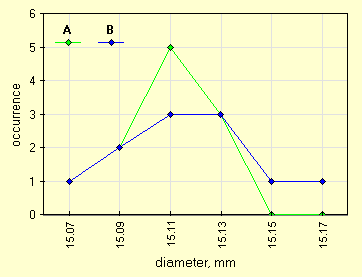 |
| 11 dati appaiati, due diversi operatori |
Uno dei grafici poco usati ma molto potenti per conforntare dei dati appaiati e' il Ladder Graph che con qualche trucco si puo' ottenere anche da uno spreadsheet. L'asse Y mostra i valori misurati. L'asse X mostra il tempo anche se con soli due punti, quello iniziale e quello finale. Ogni punto ha una retta che collega i due valori iniziale e finale. Quello qui sotto evidenzia con due colori i tratti ascendenti e discendenti.
Ladder Graph e' utile quando ci sono pochi oggetti da mostrare, una decina o poco piu'. Si nota anche l'ampiezza e il raggruppamento delle due distribuzioni sull'asse Y, delle misure.
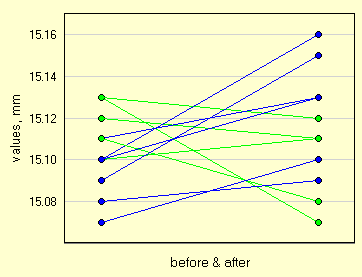 |
| Ladder Graph per 11 dati appaiati |
Questa volta sulle formule non c'e confusione. Anzi ripetiamo il calcolo di S2 che va calcolato sulle differenze.
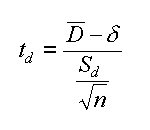 |
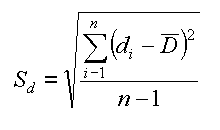 |
| t-test, 2 camp. dipend. | formula di Sd (sulle differenze) |
Lo scarto quadratico e' calcolato sulle differenze. Qualche parola bisogna spenderla sul valore di δ che puo' essere:
Visto che trattasi di una esercitazione di laboratorio non siamo troppo stringenti con le probabilita', testiamo al 80% ed al 95% (cioe' α=0.2 et α=0.05). Copiamo una tabella da un buon libro.
| One Sided | 80% | 90% | 95% | 97.5% | 99% | 99.5% | 99.75% |
| Two Sided | 60% | 80% | 90% | 95% | 98% | 99% | 99.5% |
| 10 | 0.879 | 1.372 | 1.812 | 2.228 | 2.764 | 3.169 | 3.581 |
| 11 | 0.876 | 1.363 | 1.796 | 2.201 | 2.718 | 3.106 | 3.497 |
| 12 | 0.873 | 1.356 | 1.782 | 2.179 | 2.681 | 3.055 | 3.428 |
Se abbiamo scelto una probabilita' del 80% il valore tabulato 1.363 e' maggiore di quello ottenuto 0.913 (preso come modulo) percio' l'ipotesi nulla e' accettata.
Se abbiamo scelto una probabilita' del 95% il valore tabulato 2.201 e' maggiore di quello ottenuto 0.913 percio' l'ipotesi nulla e' accettata. Cioe' possiamo scrivere: -2.201 < td < 2.201 visto che usiamo un test a due code. Cioe' non si rilevano differenze fra i due operatori che hanno svolto le misure.
Nelle misure spesso ci si trova di fronte ad un valore che non sembra far parte della distribuzione. La domanda che ci si pone e' se trattare questo dato come un outlier. Quando si sta eseguendo un campionamento, con un piccolo numero (<30 ?) di "oggetti" estratti da una popolazione finita e misurabile si puo' usare uno dei test di Gosset.
Questo non sostituisce uno dei vari test per la ricerca di outlier(s) ma si affianca ad essi. Questo test ci conferma se il valore fa parte della popolazione (oppure al contrario se fa parte di un altra popolazione).
| Extr. n. | I | II | III | IV | V | VI | VII | VIII | IX | X | XI | XII | XIII |
| values, mm | 15.09 | 15.08 | 15.13 | 15.11 | 15.07 | 15.09 | 15.13 | 15.09 | 15.12 | 15.14 | 15.11 | 15.16 | 15.12 |
Il "with replacement" NON e' avvenuto, per cui non ci sono replicati (una prima condizione del test!).
Uno dei t-test di Gosset e' quello per verificare se l'oggetto, la sua misura, fa parte della popolazione rispetto agli oggetti, le loro misure, gia' campionati. Il test e' normalmente definito con la sigla t(na-1).
Definizioni:
Calcoli:
Riaffermando che i test parametrici sono "delicati" e basta una svista per inficare un risultato, come al solito prima grafichiamo la distribuzione, visto che abbiamo un numero sufficiente di valori per formare delle classi. Usiamo un ampiezza di classe pari a due volte la risoluzione, 0.02 mm.
 |
| distribuzione per classi, 13 dati |
La null-hypothesis e' che il valore 15.07 non faccia parte della distribuzione. Usiamo il t-test di Student/Gosset per confronto fra una osservazione e la media di un campionamento.
Di formule se ne trovano tante, complesse, semplici, palesemente sbagliate, questa e' quella giusta (speriamo).
 |
 |
| una misura e' parte della distribuzione? | formula completa per uno spreadsheet |
In cui, nel caso dei 13 diametri delle provette:
Come al solito facciamo due test con probabilita' al 80% ed al 95% (cioe' α=0.2 et α=0.05). Copiamo una tabella da un buon libro.
| One Sided | 90% | 95% | 97.5% | 99% | 99.5% | 99.75% | 99.9% | 99.95% |
| Two Sided | 80% | 90% | 95% | 98% | 99% | 99.5% | 99.8% | 99.9% |
| 11 | 1.363 | 1.796 | 2.201 | 2.718 | 3.106 | 3.497 | 4.025 | 4.437 |
| 12 | 1.356 | 1.782 | 2.179 | 2.681 | 3.055 | 3.428 | 3.930 | 4.318 |
| 13 | 1.350 | 1.771 | 2.160 | 2.650 | 3.012 | 3.372 | 3.852 | 4.221 |
Se abbiamo scelto una probabilita' del 80% il valore tabulato 1.356 e' minore di quello ottenuto 1.513 percio' l'ipotesi nulla e' rigettata.
Se abbiamo scelto una probabilita' del 95% il valore tabulato 2.179 e' maggiore di quello ottenuto 1.513 percio' l'ipotesi nulla e' accettata. Cioe' possiamo scrivere: -2.179 < t < 2.179 visto che usiamo un test a due code.
Forse sarebbe piu' corretto usare una qualche tecnica di cross-validation in cui l'oggetto sotto esame non prende parte alla costruzione del modello, ne riparleremo a lezione.
Just measured Pearson's r really measure a correlation or a chance? Appena dopo aver calcolato un coefficiente di correlazione fra due variabili ci si deve chiedere se questo e' significativo o e' solo dovuto al caso.
Prendiamo il data set cosidetto "scarpeshoes", nella sua prima versione che conteneva solo 14 misure e vediamo se la correlazione ottenibile e' significativa (r=0.88056484952946).
| height, m | 1.79 | 1.58 | 1.65 | 1.65 | 1.60 | 1.86 | 1.76 | 1.63 | 1.55 | 1.80 | 1.81 | 1.54 | 1.75 | 1.65 |
| shoes num. | 39 | 37 | 38 | 37 | 38 | 43 | 43 | 37 | 37 | 44.5 | 43 | 36 | 41.5 | 37 |
Questa volta il t-test di Gosset serve per verificare che il cofficiente di correlazione r non sia dovuto al caso ma sia significativo tenendo conto del numero di misure, senza replicati. Il test e' normalmente definito con la sigla t(r).
Definizioni:
Rileggendo quanto qui sopra scritto noi imponiamo che NON ci sia correlazione nella popolazione ed attraverso il t-test ci facciamo smentire. Ma un altra null-hypothesis potrebbe essere che ρ=m, cioe' uguale ad un valore noto per la popolazione. Questo e' molto poco usato e la sua formulazione e realizzazione esula dallo scopo di queste slide.
Calcoli:
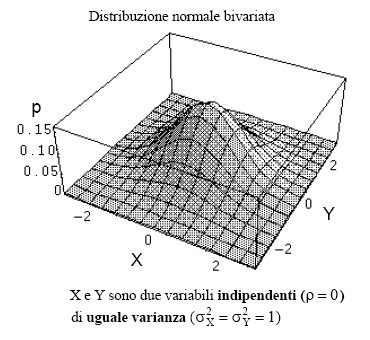
Come sempre prima qualche grafico e poi le formule da applicare. Questa volta necessita che dal bel libro on-line del Prof. L. Soliani di Parma rubiamo due disegni.
 |
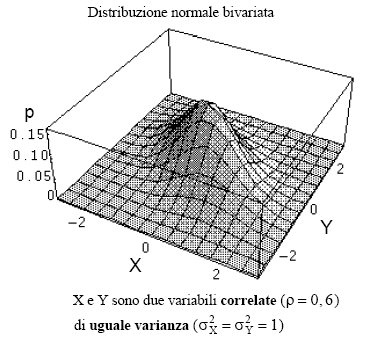 |
| doppia distribuzione gaussiana su X e su Y | ma in questo caso c'e' anche una correlazione |
Quella mostrata e' la popolazione delle X e delle Y che a sinistra mostra solo un picco di probabilita'. A destra invece la struttura e' diversa, la "montagna" si pone sulla diagonale del piano XY, si nota una correlazione. Ora come al solito grafichiamo i nostri dati.
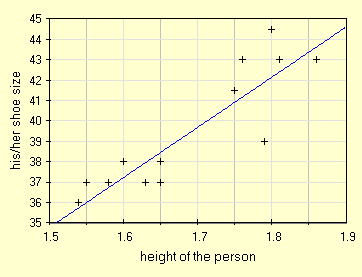 |
| con soli 14 valori sembra presente un correlazione lineare |
La formula e' gia' stata presentata precedentemente. E' appena il caso di ricordare che n-2 e' dovuto a due vincoli la variabile indipendente e la pendenza.
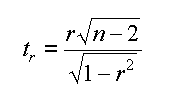 |
| significance of r |
In cui, nel caso delle 14 persone campionate:
Come al solito facciamo due test con probabilita' al 80% ed al 95% (cioe' α=0.2 et α=0.05). Copiamo una tabella da un buon libro.
| One Sided | 90% | 95% | 97.5% | 99% | 99.5% | 99.75% | 99.9% | 99.95% |
| Two Sided | 80% | 90% | 95% | 98% | 99% | 99.5% | 99.8% | 99.9% |
| 11 | 1.363 | 1.796 | 2.201 | 2.718 | 3.106 | 3.497 | 4.025 | 4.437 |
| 12 | 1.356 | 1.782 | 2.179 | 2.681 | 3.055 | 3.428 | 3.930 | 4.318 |
| 13 | 1.350 | 1.771 | 2.160 | 2.650 | 3.012 | 3.372 | 3.852 | 4.221 |
Avendo scelto una probabilita' del 80% il valore tabulato 1.356 e' minore di quello ottenuto 6.436 percio' l'ipotesi nulla e' rigettata.
Se abbiamo scelto una probabilita' del 95% il valore tabulato 2.179 e' anchesso minore di quello ottenuto 6.436 percio' l'ipotesi nulla e' rigettata. Cioe' non possiamo affermare che ρ=0, il coefficiente r e' significativo.
Prima una precisazione: sono state lasciate tutte le cifre decimali prodotte dai calcoli per permettere il confronto con altri software, chiaramente se questi numeri comparissero in una pubblicazione e/o relazione sarebbero sbagliati.
Di calcolatori on-line e di testi se ne trovano tanti, spesso sbagliati, una breve selezione pero' porta a consigliare il libro on-line del Prof. Lamberto Soliani, Universita' di Parma. Inoltre possiamo citare:
| previous slide | next slide |